Помислете за разпределението Хи-квадрат. Използване на функция MS EXCELCH2.DIST() Нека начертаем функцията на разпределение и плътността на вероятността и да обясним използването на това разпределение за целите на математическата статистика.
Хи-квадрат разпределение (X 2, XI2,английскиЧи- на квадратразпространение) използвани в различни методи на математическата статистика:
- по време на строителството;
- в ;
- при (емпиричните данни съгласуват ли се с нашето предположение за теоретичната функция на разпределение или не, англ. Goodness-of-fit)
- при (използва се за определяне на връзката между две категорични променливи, английски Хи-квадрат тест на асоцииране).
Определение: Ако x 1 , x 2 , …, x n са независими случайни променливи, разпределени върху N(0;1), тогава разпределението на случайната променлива Y=x 1 2 + x 2 2 +…+ x n 2 има разпространение X 2 с n степени на свобода.
Разпределение X 2 зависи от един наречен параметър степен на свобода (df, степенинасвобода). Например при изграждане брой степени на свободае равно на df=n-1, където n е размерът проби.
Плътност на разпространение X 2
изразено с формулата:
Функционални графики
Разпределение X 2 има асиметрична форма, равна на n, равна на 2n.
IN примерен файл в графичния листдадено графики на плътността на разпределениетовероятности и кумулативна функция на разпределение.

Полезен имот CH2 разпределения
Нека x 1 , x 2 , …, x n са независими случайни променливи, разпределени в нормален закон
със същите параметри μ и σ, и X сре средно аритметичнотези x стойности.
Тогава случайна променлива гравен
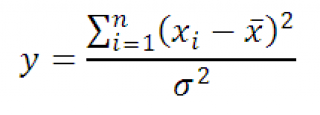
Има X 2 -разпределениес n-1 степени на свобода. Използвайки дефиницията, горният израз може да бъде пренаписан както следва:

следователно разпределение на пробитестатистика y, at пробаот нормално разпределение, има X 2 -разпределениес n-1 степени на свобода.
Ще имаме нужда от този имот, когато. защото дисперсияможе да бъде само положително число и X 2 -разпределениетогава се използва за оценката му гд.б. >0, както е посочено в дефиницията.
CH2 разпределение в MS EXCEL
В MS EXCEL, започвайки от версия 2010, за X 2 -разпределенияима специална функция CHI2.DIST(), английско име– CHISQ.DIST(), което ви позволява да изчислявате плътност на вероятността(вижте формулата по-горе) и (вероятността една случайна променлива X да има CI2-разпространение, ще приеме стойност, по-малка или равна на x, P(X<= x}).
Забележка: Защото CH2 разпределениее частен случай, тогава формулата =GAMMA.DIST(x;n/2;2;TRUE)за положително цяло число n връща същия резултат като формулата =CHI2.DIST(x;n; TRUE)или =1-CHI2.DIST.PH(x;n) . И формулата =GAMMA.DIST(x;n/2;2;FALSE)връща същия резултат като формулата =CHI2.DIST(x;n; FALSE), т.е. плътност на вероятността CH2 разпределения.
Функцията HI2.DIST.PH() връща разпределителна функция, по-точно дясностранна вероятност, т.е. P(X > x). Очевидно е, че равенството е вярно
=CHI2.DIST.PH(x;n)+CHI2.DIST(x;n;TRUE)=1
защото първият член изчислява вероятността P(X > x), а вторият P(X<= x}.
Преди MS EXCEL 2010, EXCEL имаше само функцията CH2DIST(), която ви позволява да изчислите дясната вероятност, т.е. P(X > x). Възможностите на новите функции на MS EXCEL 2010 XI2.DIST() и XI2.DIST.PH() покриват възможностите на тази функция. Функцията CH2DIST() е оставена в MS EXCEL 2010 за съвместимост.
CHI2.DIST() е единствената функция, която връща плътност на вероятността на разпределението chi2(третият аргумент трябва да е FALSE). Останалите функции се връщат кумулативна функция на разпределение, т.е. вероятност случайната променлива да приеме стойност от посочения диапазон: P(X<= x}.
Горните функции на MS EXCEL са дадени в .
Примери
Нека намерим вероятността случайната променлива X да приеме стойност, по-малка или равна на дадената х: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x; n; TRUE)
=1-HI2.DIST.PH(x; n)
=1-CHI2DIST(x; n)
Функцията CH2.DIST.PH() връща вероятността P(X > x), така наречената дясна вероятност, така че да се намери P(X<= x}, необходимо вычесть ее результат от 1.
Нека намерим вероятността случайната променлива X да приеме стойност, по-голяма от дадена х: P(X > x). Това може да стане с няколко функции:
1-CHI2.DIST(x; n; TRUE)
=HI2.DIST.PH(x; n)
=CHI2DIST(x; n)
Обратна функция на разпределение chi2
За изчисляване се използва обратната функция алфа- , т.е. за изчисляване на стойности хза дадена вероятност алфа, и Xтрябва да отговаря на израза P(X<= x}=алфа.
Функцията CH2.INV() се използва за изчисляване доверителни интервали на дисперсията на нормалното разпределение.
Функцията CHI2.OBR.PH() се използва за изчисляване, т.е. ако ниво на значимост е указано като аргумент на функцията, например 0,05, тогава функцията ще върне стойност на случайната променлива x, за която P(X>x)=0,05. За сравнение: функцията XI2.INR() ще върне стойност на случайната променлива x, за която P(X<=x}=0,05.
В MS EXCEL 2007 и по-рано, вместо HI2.OBR.PH(), се използва функцията HI2OBR().
Горните функции могат да се сменят, т.к следните формули връщат същия резултат:
=CHI.OBR(алфа;n)
=HI2.OBR.PH(1-алфа;n)
=CHI2INV(1- алфа;n)
Някои примери за изчисления са дадени в примерен файл в листа с функции.
MS EXCEL функционира, използвайки CH2 разпределението
По-долу е съответствието между руски и английски имена на функции:
CH2.DIST.PH() - английски. име CHISQ.DIST.RT, т.е. ХИ-квадратно РАЗПРЕДЕЛЕНИЕ Дясна опашка, дясноразпределение Хи-квадрат(d)
CH2.OBR() - английски. име CHISQ.INV, т.е. CHI-квадратно разпределение INVerse
CH2.PH.OBR() - английски. име CHISQ.INV.RT, т.е. CHI-квадратно разпределение INVerse Right Tail
CH2DIST() - английски. име CHIDIST, функция, еквивалентна на CHISQ.DIST.RT
CH2OBR() - английски. име CHIINV, т.е. CHI-квадратно разпределение INVerse
Оценка на параметрите на разпределението
защото обикновено CH2 разпределениеизползвани за целите на математическата статистика (изчисление доверителни интервали, тестване на хипотези и др.),и почти никога за конструиране на модели на реални стойности, тогава за това разпределение обсъждането на оценката на параметрите на разпределението не се провежда тук.
Апроксимация на разпределението на CI2 чрез нормалното разпределение
С броя на степените на свобода n>30 разпределение X 2добре приблизително нормално разпределениес средна стойностμ=n и дисперсия σ=2*n (вижте примерен листов файл Приближение).
Тестът \(\chi^2\) ("хи-квадрат", също "тест за съответствие на Пиърсън") има изключително широко приложение в статистиката. Най-общо можем да кажем, че се използва за тестване на нулевата хипотеза, че наблюдавана случайна променлива е обект на определен теоретичен закон за разпределение (за повече подробности вижте например). Конкретната формулировка на тестваната хипотеза ще варира в зависимост от случая.
В тази публикация ще опиша как работи критерият \(\chi^2\), като използвам (хипотетичен) пример от имунологията. Нека си представим, че сме провели експеримент, за да установим ефективността на потискане на развитието на микробно заболяване, когато в тялото се въведат подходящи антитела. В експеримента участваха общо 111 мишки, които разделихме на две групи, включващи съответно 57 и 54 животни. На първата група мишки бяха инжектирани патогенни бактерии, последвано от въвеждане на кръвен серум, съдържащ антитела срещу тези бактерии. Животните от втората група послужиха за контрола - те получиха само бактериални инжекции. След известно време на инкубация се оказа, че 38 мишки са умрели, а 73 са оцелели. От загиналите 13 са от първа група, а 25 от втора (контролна). Нулевата хипотеза, тествана в този експеримент, може да бъде формулирана по следния начин: прилагането на серум с антитела няма ефект върху оцеляването на мишките. С други думи, ние твърдим, че наблюдаваните разлики в преживяемостта на мишките (77,2% в първата група срещу 53,7% във втората група) са напълно случайни и не са свързани с ефекта на антителата.
Получените в експеримента данни могат да бъдат представени под формата на таблица:
Общо |
|||
Бактерии + серум |
|||
Само бактерии |
|||
Общо |
Таблици като показаната се наричат таблици за непредвидени случаи. В разглеждания пример таблицата е с размери 2x2: има два класа обекти („Бактерии + серум“ и „Само бактерии“), които се изследват по два критерия („Мъртви“ и „Оцелели“). Това е най-простият случай на таблица за непредвидени обстоятелства: разбира се, както броят на изучаваните класове, така и броят на функциите може да бъде по-голям.
За да тестваме нулевата хипотеза, посочена по-горе, трябва да знаем каква би била ситуацията, ако антителата действително нямаха ефект върху оцеляването на мишките. С други думи, трябва да изчислите очаквани честотиза съответните клетки от таблицата за непредвидени обстоятелства. Как да стане това? В експеримента са загинали общо 38 мишки, което е 34,2% от общия брой на участващите животни. Ако прилагането на антитела не повлиява преживяемостта на мишките, трябва да се наблюдава еднакъв процент на смъртност и в двете експериментални групи, а именно 34,2%. Изчислявайки колко е 34,2% от 57 и 54, получаваме 19,5 и 18,5. Това са очакваните нива на смъртност в нашите експериментални групи. Очакваните нива на оцеляване се изчисляват по подобен начин: тъй като са оцелели общо 73 мишки или 65,8% от общия брой, очакваните нива на оцеляване ще бъдат 37,5 и 35,5. Нека създадем нова таблица за непредвидени обстоятелства, сега с очакваните честоти:
Мъртъв |
Оцелели |
Общо |
|
Бактерии + серум |
|||
Само бактерии |
|||
Общо |
Както виждаме, очакваните честоти са доста различни от наблюдаваните, т.е. прилагането на антитела изглежда има ефект върху оцеляването на мишки, заразени с патогена. Можем да определим количествено това впечатление с помощта на теста за съответствие на Pearson \(\chi^2\):
\[\chi^2 = \sum_()\frac((f_o - f_e)^2)(f_e),\]
където \(f_o\) и \(f_e\) са съответно наблюдаваните и очакваните честоти. Сумирането се извършва по всички клетки на таблицата. Така че за разглеждания пример имаме
\[\chi^2 = (13 – 19,5)^2/19,5 + (44 – 37,5)^2/37,5 + (25 – 18,5)^2/18,5 + (29 – 35,5)^2/35,5 = \]
Получената стойност на \(\chi^2\) достатъчно голяма ли е, за да отхвърли нулевата хипотеза? За да се отговори на този въпрос е необходимо да се намери съответната критична стойност на критерия. Броят на степените на свобода за \(\chi^2\) се изчислява като \(df = (R - 1)(C - 1)\), където \(R\) и \(C\) са числото на редове и колони в конюгацията на таблицата. В нашия случай \(df = (2 -1)(2 - 1) = 1\). Като знаем броя на степените на свобода, сега можем лесно да намерим критичната стойност \(\chi^2\), като използваме стандартната R функция qchisq() :
Така при една степен на свобода само в 5% от случаите стойността на критерия \(\chi^2\) надвишава 3,841. Стойността, която получихме, 6,79, значително надвишава тази критична стойност, което ни дава право да отхвърлим нулевата хипотеза, че няма връзка между прилагането на антитела и оцеляването на заразените мишки. Отхвърляйки тази хипотеза, рискуваме да сгрешим с вероятност по-малка от 5%.
Трябва да се отбележи, че горната формула за критерия \(\chi^2\) дава леко завишени стойности при работа с таблици за непредвидени обстоятелства с размер 2x2. Причината е, че разпределението на самия критерий \(\chi^2\) е непрекъснато, докато честотите на двоичните характеристики („умрял“ / „оцелял“) са по дефиниция дискретни. В тази връзка при изчисляване на критерия е прието да се въвежда т.нар корекция на непрекъснатостта, или Поправката на Йейтс :
\[\chi^2_Y = \sum_()\frac((|f_o - f_e| - 0,5)^2)(f_e).\]
Пиърсън "s Хи-квадрат тест с Йейтс"данни за корекция на непрекъснатостта: мишки X-квадрат = 5,7923, df = 1, p-стойност = 0,0161
Както виждаме, R автоматично прилага корекцията за непрекъснатост на Йейтс ( Хи-квадрат тест на Пиърсън с корекция за непрекъснатост на Йейтс). Стойността на \(\chi^2\), изчислена от програмата, беше 5,79213. Можем да отхвърлим нулевата хипотеза за липса на ефект на антитела с риск да сгрешим с вероятност от малко над 1% (p-стойност = 0,0161).
Министерство на образованието и науката на Руската федерация
Федерална агенция за образование на град Иркутск
Байкалски държавен университет по икономика и право
Катедра "Информатика и кибернетика".
Хи-квадрат разпределение и неговите приложения
Колмикова Анна Андреевна
Студентка 2-ра година
група ИС-09-1
За обработка на получените данни използваме теста хи-квадрат.
За да направим това, ще изградим таблица на разпределението на емпиричните честоти, т.е. тези честоти, които наблюдаваме:
Теоретично очакваме, че честотите ще бъдат равномерно разпределени, т.е. честотата ще бъде разпределена пропорционално между момчета и момичета. Нека изградим таблица с теоретични честоти. За да направите това, умножете сумата на реда по сумата на колоната и разделете полученото число на общата сума (s).
Финалната таблица за изчисления ще изглежда така:
χ2 = ∑(E - T)² / T
n = (R - 1), където R е броят на редовете в таблицата.
В нашия случай хи-квадрат = 4,21; n = 2.
Използвайки таблицата с критични стойности на критерия, намираме: с n = 2 и ниво на грешка от 0,05, критичната стойност е χ2 = 5,99.
Получената стойност е по-малка от критичната стойност, което означава, че нулевата хипотеза е приета.
Извод: учителите не отдават значение на пола на детето, когато пишат характеристики за него.
Приложение
Критични точки на разпределението χ2
Таблица 1

Заключение
Студентите от почти всички специалности изучават раздела „Теория на вероятностите и математическа статистика” в края на курса по висша математика, в действителност те се запознават само с някои основни понятия и резултати, които очевидно не са достатъчни за практическа работа. Студентите се запознават с някои математически изследователски методи в специални курсове (например „Прогнозиране и технико-икономическо планиране“, „Технико-икономически анализ“, „Контрол на качеството на продуктите“, „Маркетинг“, „Контрол“, „Математически методи за прогнозиране“ ”), „Статистика“ и др. – при студенти от икономически специалности), но представянето в повечето случаи е много съкратено и шаблонно. В резултат на това знанията на специалистите по приложна статистика са недостатъчни.
Ето защо курсът „Приложна статистика” в техническите университети е от голямо значение, а курсът „Иконометрия” в икономическите университети, тъй като иконометрията, както е известно, е статистически анализ на конкретни икономически данни.
Теорията на вероятностите и математическата статистика предоставят фундаментални знания за приложна статистика и иконометрия.
Те са необходими на специалистите за практическа работа.
Разгледах непрекъснатия вероятностен модел и се опитах да покажа използването му с примери.
Списък на използваната литература
1. Орлов А.И. Приложна статистика. М.: Издателство "Изпит", 2004 г.
2. Гмурман В.Е. Теория на вероятностите и математическа статистика. М.: Висше училище, 1999. – 479 с.
3. Айвозян С.А. Теория на вероятностите и приложна статистика, том 1. М.: Единство, 2001. – 656 с.
4. Хамитов Г.П., Ведерникова Т.И. Вероятности и статистики. Иркутск: BGUEP, 2006 – 272 с.
5. Ежова Л.Н. Иконометрия. Иркутск: BGUEP, 2002. – 314 с.
6. Мостелер Ф. Петдесет забавни вероятностни задачи с решения. М.: Наука, 1975. – 111 с.
7. Мостелер Ф. Вероятност. М.: Мир, 1969. – 428 с.
8. Яглом А.М. Вероятност и информация. М.: Наука, 1973. – 511 с.
9. Чистяков В.П. Курс по теория на вероятностите. М.: Наука, 1982. – 256 с.
10. Кремер Н.Ш. Теория на вероятностите и математическа статистика. М.: ЕДИНСТВО, 2000. – 543 с.
11. Математическа енциклопедия, кн.1. М.: Съветска енциклопедия, 1976. – 655 с.
12. http://psystat.at.ua/ - Статистика в психологията и педагогиката. Статия Хи-квадрат тест.
До края на 19-ти век нормалното разпределение се смяташе за универсален закон за изменението на данните. К. Пиърсън обаче отбеляза, че емпиричните честоти могат да се различават значително от нормалното разпределение. Възникна въпросът как да се докаже това. Изисква се не само графично сравнение, което е субективно, но и стриктна количествена обосновка.
Така е измислен критерият χ 2(хи квадрат), който тества значимостта на несъответствието между емпирични (наблюдавани) и теоретични (очаквани) честоти. Това се случи още през 1900 г., но критерият се използва и днес. Освен това той е адаптиран за решаване на широк кръг от проблеми. На първо място, това е анализ на категорични данни, т.е. тези, които се изразяват не чрез количество, а чрез принадлежност към някаква категория. Например класа на автомобила, пола на участника в експеримента, вида на растението и др. Математически операции като събиране и умножение не могат да бъдат приложени към такива данни; честотите могат да бъдат изчислени само за тях.
Означаваме наблюдаваните честоти Относно (Наблюдавано), очаквано – E (Очаква се). Като пример, нека вземем резултата от хвърляне на зар 60 пъти. Ако е симетрична и еднаква, вероятността да се получи която и да е страна е 1/6 и следователно очакваният брой да се получи всяка страна е 10 (1/6∙60). Записваме наблюдаваните и очакваните честоти в таблица и чертаем хистограма.

Нулевата хипотеза е, че честотите са последователни, тоест действителните данни не противоречат на очакваните данни. Алтернативна хипотеза е, че отклоненията в честотите надхвърлят случайните флуктуации, несъответствията са статистически значими. За да направим строго заключение, имаме нужда.
- Обобщена мярка за несъответствието между наблюдаваните и очакваните честоти.
- Разпределението на тази мярка, ако хипотезата, че няма разлики е вярна.
Да започнем с разстоянието между честотите. Ако просто вземете разликата О - Е, тогава такава мярка ще зависи от мащаба на данните (честотите). Например 20 - 5 = 15 и 1020 - 1005 = 15. И в двата случая разликата е 15. Но в първия случай очакваните честоти са 3 пъти по-малки от наблюдаваните, а във втория случай - само 1,5 %. Нуждаем се от относителна мярка, която не зависи от мащаба.
Нека обърнем внимание на следните факти. Като цяло, броят на категориите, в които се измерват честотите, може да бъде много по-голям, така че вероятността едно наблюдение да попадне в една или друга категория е доста малка. Ако е така, тогава разпределението на такава случайна променлива ще се подчинява на закона за редките събития, известен като Закон на Поасон. В закона на Поасон, както е известно, стойността на математическото очакване и дисперсията съвпадат (параметър λ ). Това означава, че очакваната честота за някоя категория на номиналната променлива E iще бъде едновременно и неговата дисперсия. Освен това законът на Поасон клони към нормален при голям брой наблюдения. Комбинирайки тези два факта, получаваме, че ако хипотезата за съответствието между наблюдаваните и очакваните честоти е вярна, тогава, с голям брой наблюдения, израз
Важно е да запомните, че нормалното ще се появи само при достатъчно високи честоти. В статистиката е общоприето, че общият брой наблюдения (сума от честоти) трябва да бъде най-малко 50 и очакваната честота във всяка градация трябва да бъде най-малко 5. Само в този случай стойността, показана по-горе, има стандартно нормално разпределение . Да приемем, че това условие е изпълнено.
Стандартното нормално разпределение има почти всички стойности в рамките на ±3 (правилото на трите сигми). Така получихме относителната разлика в честотите за една градация. Имаме нужда от обобщаваща мярка. Не можете просто да съберете всички отклонения - получаваме 0 (познайте защо). Пиърсън предложи да се съберат квадратите на тези отклонения.
![]()
Това е знакът Хи-квадрат тест Пиърсън. Ако честотите наистина отговарят на очакваните, тогава стойността на критерия ще бъде относително малка (тъй като повечето отклонения са около нулата). Но ако критерият се окаже голям, тогава това показва значителни разлики между честотите.
Критерият на Pearson става „голям“, когато появата на такава или дори по-голяма стойност стане малко вероятна. И за да се изчисли такава вероятност, е необходимо да се знае разпределението на критерия, когато експериментът се повтаря многократно, когато хипотезата за съответствие на честотата е вярна.
Както е лесно да се види, стойността на хи-квадрат също зависи от броя на членовете. Колкото повече са, толкова по-голяма стойност трябва да има критерият, тъй като всеки член ще допринесе за общата сума. Следователно за всяко количество независимаусловия, ще има собствено разпространение. Оказва се, че χ 2е цяло семейство от дистрибуции.
И тук стигаме до един деликатен момент. Какво е число независимаусловия? Изглежда, че всеки термин (т.е. отклонение) е независим. Така смяташе и К. Пиърсън, но се оказа, че греши. Всъщност броят на независимите членове ще бъде с един по-малък от броя на градациите на номиналната променлива п. защо Защото, ако имаме извадка, за която сумата от честотите вече е изчислена, тогава една от честотите винаги може да бъде определена като разликата между общия брой и сумата от всички останали. Следователно вариацията ще бъде малко по-малка. Роналд Фишър забеляза този факт 20 години след като Пиърсън разработи своя критерий. Дори масите трябваше да бъдат преправени.
По този повод Фишър въвежда нова концепция в статистиката - степен на свобода(степени на свобода), което представлява броя на независимите членове в сумата. Концепцията за степените на свобода има математическо обяснение и се появява само в разпределения, свързани с нормалното (на Стюдънт, на Фишер-Снедекор и самото хи-квадрат).
За да разберем по-добре значението на степените на свобода, нека се обърнем към един физически аналог. Нека си представим точка, която се движи свободно в пространството. Има 3 степени на свобода, т.к може да се движи във всяка посока в триизмерното пространство. Ако една точка се движи по която и да е повърхност, тогава тя вече има две степени на свобода (напред и назад, наляво и надясно), въпреки че продължава да бъде в триизмерното пространство. Точка, движеща се по пружина, отново е в триизмерно пространство, но има само една степен на свобода, т.к може да се движи напред или назад. Както можете да видите, пространството, където се намира обектът, не винаги отговаря на реалната свобода на движение.
Приблизително по същия начин разпределението на статистически критерий може да зависи от по-малък брой елементи от условията, необходими за изчисляването му. Като цяло броят на степените на свобода е по-малък от броя на наблюденията с броя на съществуващите зависимости.
По този начин разпределението хи квадрат ( χ 2) е семейство от разпределения, всяко от които зависи от параметъра за степени на свобода. А формалната дефиниция на теста хи-квадрат е следната. Разпределение χ 2(хи-квадрат) s кстепени на свобода е разпределението на сумата от квадрати кнезависими стандартни нормални случайни променливи.
След това бихме могли да преминем към самата формула, чрез която се изчислява функцията на разпределение хи-квадрат, но за щастие всичко отдавна е изчислено за нас. За да получите вероятността от интерес, можете да използвате или подходящата статистическа таблица, или готова функция в Excel.
Интересно е да се види как формата на разпределението хи-квадрат се променя в зависимост от броя на степените на свобода.

С увеличаване на степените на свобода разпределението хи-квадрат има тенденция да бъде нормално. Това се обяснява с действието на централната гранична теорема, според която сумата от голям брой независими случайни променливи има нормално разпределение. Не пише нищо за квадрати)).
Тестване на хипотезата с помощта на хи-квадрат теста на Pearson
Сега стигаме до тестване на хипотези с помощта на метода хи-квадрат. Като цяло технологията остава. Нулевата хипотеза е, че наблюдаваните честоти съответстват на очакваните (т.е. няма разлика между тях, защото са взети от една и съща популация). Ако това е така, тогава разсейването ще бъде относително малко, в рамките на случайните колебания. Мярката за дисперсия се определя с помощта на теста хи-квадрат. След това или самият критерий се сравнява с критичната стойност (за съответното ниво на значимост и степени на свобода), или, което е по-правилно, се изчислява наблюдаваната p-стойност, т.е. вероятността да се получи същата или дори по-голяма стойност на критерия, ако нулевата хипотеза е вярна.

защото интересуваме се от съответствието на честотите, тогава хипотезата ще бъде отхвърлена, когато критерият е по-голям от критичното ниво. Тези. критерият е едностранен. Въпреки това понякога (понякога) е необходимо да се тества лявата хипотеза. Например, когато емпиричните данни са много сходни с теоретичните данни. Тогава критерият може да попадне в малко вероятна област, но отляво. Факт е, че при естествени условия е малко вероятно да се получат честоти, които практически съвпадат с теоретичните. Винаги има някаква случайност, която дава грешка. Но ако няма такава грешка, тогава може би данните са фалшифицирани. Но все пак хипотезата за дясната страна обикновено се тества.
Да се върнем на проблема със заровете. Нека изчислим стойността на теста хи-квадрат, като използваме наличните данни.
Сега нека намерим критичната стойност при 5 степени на свобода ( к) и ниво на значимост 0,05 ( α ) според таблицата на критичните стойности на разпределението хи квадрат.

Тоест 0,05 квантилно разпределение хи квадрат (дясна опашка) с 5 степени на свобода χ 2 0,05; 5 = 11,1.
Нека сравним действителните и табличните стойности. 3.4 ( χ 2) < 11,1 (χ 2 0,05; 5). Изчисленият критерий се оказа по-малък, което означава, че не се отхвърля хипотезата за равенство (съгласуване) на честотите. На фигурата ситуацията изглежда така.

Ако изчислената стойност попада в критичната област, нулевата хипотеза ще бъде отхвърлена.
Би било по-правилно да се изчисли и p-стойността. За да направите това, трябва да намерите най-близката стойност в таблицата за даден брой степени на свобода и да разгледате съответното ниво на значимост. Но това е миналия век. Ще използваме компютър, по-специално MS Excel. Excel има няколко функции, свързани с хи-квадрат.

По-долу е дадено кратко описание за тях.
CH2.OBR– критична стойност на критерия при дадена вероятност отляво (както в статистическите таблици)
CH2.OBR.PH– критична стойност на критерия за дадена вероятност отдясно. Функцията по същество дублира предишната. Но тук можете веднага да посочите нивото α , вместо да го извадите от 1. Това е по-удобно, защото в повечето случаи е необходима дясната опашка на разпределението.
CH2.DIST– p-стойност отляво (плътността може да се изчисли).
CH2.DIST.PH– p-стойност вдясно.
CHI2.ТЕСТ– незабавно провежда хи-квадрат тест за два честотни диапазона. Броят на степените на свобода се приема с една по-малък от броя на честотите в колоната (както трябва да бъде), като се връща p-стойност.
Нека изчислим за нашия експеримент критичната (таблична) стойност за 5 степени на свобода и алфа 0,05. Формулата на Excel ще изглежда така:
CH2.OBR(0,95;5)
CH2.OBR.PH(0,05;5)
Резултатът ще бъде същият - 11.0705. Това е стойността, която виждаме в таблицата (закръглена до 1 знак след десетичната запетая).
Нека накрая изчислим p-стойността за критерия за 5 степени на свобода χ 2= 3,4. Имаме нужда от вероятност отдясно, така че вземаме функция с добавяне на HH (дясна опашка)
CH2.DIST.PH(3,4;5) = 0,63857
Това означава, че при 5 степени на свобода вероятността за получаване на стойността на критерия е χ 2= 3,4 и повече е равно на почти 64%. Естествено, хипотезата не е отхвърлена (p-стойността е по-голяма от 5%), честотите са в много добро съответствие.
Сега нека проверим хипотезата за съответствието на честотите с помощта на теста хи-квадрат и функцията на Excel CHI2.TEST.

Без таблици, без тромави изчисления. Като посочим колони с наблюдавани и очаквани честоти като аргументи на функцията, веднага получаваме p-стойността. красота.
Сега си представете, че играете на зарове с подозрителен човек. Разпределението на точките от 1 до 5 остава същото, но той хвърля 26 шестици (общият брой хвърляния става 78).

P-стойността в този случай се оказва 0,003, което е много по-малко от 0,05. Има основателни причини да се съмнявате в валидността на заровете. Ето как изглежда тази вероятност на диаграма за разпределение хи-квадрат.

Самият хи-квадрат тест тук се оказва 17,8, което естествено е по-голямо от табличното (11,1).
Надявам се, че успях да обясня какъв е критерият за съгласие χ 2(хи-квадрат на Пиърсън) и как може да се използва за тестване на статистически хипотези.
И накрая, още веднъж за важно условие! Тестът хи-квадрат работи правилно само когато броят на всички честоти надвишава 50 и минималната очаквана стойност за всяка градация е не по-малка от 5. Ако в която и да е категория очакваната честота е по-малка от 5, но сумата от всички честоти надвишава 50, тогава тази категория се комбинира с най-близката, така че общата им честота да надвишава 5. Ако това не е възможно или сумата на честотите е по-малка от 50, тогава трябва да се използват по-точни методи за проверка на хипотези. За тях ще говорим друг път.
По-долу има видеоклип за това как да тествате хипотеза в Excel с помощта на теста хи-квадрат.
Нека U 1, U 2, ..,U k са независими стандартни нормални стойности. Разпределението на случайната променлива K = U 1 2 +U 2 2 + .. + U k 2 се нарича разпределение хи-квадрат с кстепени на свобода (напишете K~χ 2 (k)). Това е унимодално разпределение с положителна асиметрия и следните характеристики: режим M=k-2 математическо очакване m=k дисперсия D=2k (фиг.). При достатъчно голяма стойност на параметъра кразпределението χ 2 (k) има приблизително нормално разпределение с параметри
При решаване на задачи на математическата статистика се използват критични точки χ 2 (k), в зависимост от дадената вероятност α и броя на степените на свобода к(Приложение 2). Критичната точка Χ 2 kr = Χ 2 (k; α) е границата на областта, вдясно от която лежи 100-α % от площта под кривата на плътността на разпределението. Вероятността стойността на случайната променлива K~χ 2 (k) по време на тестването да падне вдясно от точката χ 2 (k) не надвишава α P(K≥χ 2 kp)≤ α). Например за случайната променлива K~χ 2 (20) задаваме вероятността α=0,05. Използвайки таблицата на критичните точки на разпределението хи-квадрат (таблици), намираме χ 2 kp = χ 2 (20;0,05) = 31,4. Това означава, че вероятността на тази случайна променлива Квземете стойност, по-голяма от 31,4, по-малка от 0,05 (фиг.). 
ориз. Графика на плътността на разпределение χ 2 (k) за различни стойности на броя на степените на свобода к
Критичните точки χ 2 (k) се използват в следните калкулатори:
- Проверка за мултиколинеарност (относно мултиколинеарността).
Следователно, за да се провери посоката на връзката, се избира корелационен анализ, по-специално тестване на хипотезата с помощта на коефициента на корелация на Pearson с по-нататъшно тестване за значимост с помощта на t-теста.
За всяка стойност на нивото на значимост α Χ 2 може да се намери с помощта на функцията на MS Excel: =HI2OBR(α;степени на свобода)
| n-1 | .995 | .990 | .975 | .950 | .900 | .750 | .500 | .250 | .100 | .050 | .025 | .010 | .005 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.00004 | 0.00016 | 0.00098 | 0.00393 | 0.01579 | 0.10153 | 0.45494 | 1.32330 | 2.70554 | 3.84146 | 5.02389 | 6.63490 | 7.87944 |
| 2 | 0.01003 | 0.02010 | 0.05064 | 0.10259 | 0.21072 | 0.57536 | 1.38629 | 2.77259 | 4.60517 | 5.99146 | 7.37776 | 9.21034 | 10.59663 |
| 3 | 0.07172 | 0.11483 | 0.21580 | 0.35185 | 0.58437 | 1.21253 | 2.36597 | 4.10834 | 6.25139 | 7.81473 | 9.34840 | 11.34487 | 12.83816 |
| 4 | 0.20699 | 0.29711 | 0.48442 | 0.71072 | 1.06362 | 1.92256 | 3.35669 | 5.38527 | 7.77944 | 9.48773 | 11.14329 | 13.27670 | 14.86026 |
| 5 | 0.41174 | 0.55430 | 0.83121 | 1.14548 | 1.61031 | 2.67460 | 4.35146 | 6.62568 | 9.23636 | 11.07050 | 12.83250 | 15.08627 | 16.74960 |
| 6 | 0.67573 | 0.87209 | 1.23734 | 1.63538 | 2.20413 | 3.45460 | 5.34812 | 7.84080 | 10.64464 | 12.59159 | 14.44938 | 16.81189 | 18.54758 |
| 7 | 0.98926 | 1.23904 | 1.68987 | 2.16735 | 2.83311 | 4.25485 | 6.34581 | 9.03715 | 12.01704 | 14.06714 | 16.01276 | 18.47531 | 20.27774 |
| 8 | 1.34441 | 1.64650 | 2.17973 | 2.73264 | 3.48954 | 5.07064 | 7.34412 | 10.21885 | 13.36157 | 15.50731 | 17.53455 | 20.09024 | 21.95495 |
| 9 | 1.73493 | 2.08790 | 2.70039 | 3.32511 | 4.16816 | 5.89883 | 8.34283 | 11.38875 | 14.68366 | 16.91898 | 19.02277 | 21.66599 | 23.58935 |
| 10 | 2.15586 | 2.55821 | 3.24697 | 3.94030 | 4.86518 | 6.73720 | 9.34182 | 12.54886 | 15.98718 | 18.30704 | 20.48318 | 23.20925 | 25.18818 |
| 11 | 2.60322 | 3.05348 | 3.81575 | 4.57481 | 5.57778 | 7.58414 | 10.34100 | 13.70069 | 17.27501 | 19.67514 | 21.92005 | 24.72497 | 26.75685 |
| 12 | 3.07382 | 3.57057 | 4.40379 | 5.22603 | 6.30380 | 8.43842 | 11.34032 | 14.84540 | 18.54935 | 21.02607 | 23.33666 | 26.21697 | 28.29952 |
| 13 | 3.56503 | 4.10692 | 5.00875 | 5.89186 | 7.04150 | 9.29907 | 12.33976 | 15.98391 | 19.81193 | 22.36203 | 24.73560 | 27.68825 | 29.81947 |
| 14 | 4.07467 | 4.66043 | 5.62873 | 6.57063 | 7.78953 | 10.16531 | 13.33927 | 17.11693 | 21.06414 | 23.68479 | 26.11895 | 29.14124 | 31.31935 |
| 15 | 4.60092 | 5.22935 | 6.26214 | 7.26094 | 8.54676 | 11.03654 | 14.33886 | 18.24509 | 22.30713 | 24.99579 | 27.48839 | 30.57791 | 32.80132 |
| 16 | 5.14221 | 5.81221 | 6.90766 | 7.96165 | 9.31224 | 11.91222 | 15.33850 | 19.36886 | 23.54183 | 26.29623 | 28.84535 | 31.99993 | 34.26719 |
| 17 | 5.69722 | 6.40776 | 7.56419 | 8.67176 | 10.08519 | 12.79193 | 16.33818 | 20.48868 | 24.76904 | 27.58711 | 30.19101 | 33.40866 | 35.71847 |
| 18 | 6.26480 | 7.01491 | 8.23075 | 9.39046 | 10.86494 | 13.67529 | 17.33790 | 21.60489 | 25.98942 | 28.86930 | 31.52638 | 34.80531 | 37.15645 |
| 19 | 6.84397 | 7.63273 | 8.90652 | 10.11701 | 11.65091 | 14.56200 | 18.33765 | 22.71781 | 27.20357 | 30.14353 | 32.85233 | 36.19087 | 38.58226 |
| 20 | 7.43384 | 8.26040 | 9.59078 | 10.85081 | 12.44261 | 15.45177 | 19.33743 | 23.82769 | 28.41198 | 31.41043 | 34.16961 | 37.56623 | 39.99685 |
| 21 | 8.03365 | 8.89720 | 10.28290 | 11.59131 | 13.23960 | 16.34438 | 20.33723 | 24.93478 | 29.61509 | 32.67057 | 35.47888 | 38.93217 | 41.40106 |
| 22 | 8.64272 | 9.54249 | 10.98232 | 12.33801 | 14.04149 | 17.23962 | 21.33704 | 26.03927 | 30.81328 | 33.92444 | 36.78071 | 40.28936 | 42.79565 |
| 23 | 9.26042 | 10.19572 | 11.68855 | 13.09051 | 14.84796 | 18.13730 | 22.33688 | 27.14134 | 32.00690 | 35.17246 | 38.07563 | 41.63840 | 44.18128 |
| 24 | 9.88623 | 10.85636 | 12.40115 | 13.84843 | 15.65868 | 19.03725 | 23.33673 | 28.24115 | 33.19624 | 36.41503 | 39.36408 | 42.97982 | 45.55851 |
| 25 | 10.51965 | 11.52398 | 13.11972 | 14.61141 | 16.47341 | 19.93934 | 24.33659 | 29.33885 | 34.38159 | 37.65248 | 40.64647 | 44.31410 | 46.92789 |
| 26 | 11.16024 | 12.19815 | 13.84390 | 15.37916 | 17.29188 | 20.84343 | 25.33646 | 30.43457 | 35.56317 | 38.88514 | 41.92317 | 45.64168 | 48.28988 |
| 27 | 11.80759 | 12.87850 | 14.57338 | 16.15140 | 18.11390 | 21.74940 | 26.33634 | 31.52841 | 36.74122 | 40.11327 | 43.19451 | 46.96294 | 49.64492 |
| 28 | 12.46134 | 13.56471 | 15.30786 | 16.92788 | 18.93924 | 22.65716 | 27.33623 | 32.62049 | 37.91592 | 41.33714 | 44.46079 | 48.27824 | 50.99338 |
| 29 | 13.12115 | 14.25645 | 16.04707 | 17.70837 | 19.76774 | 23.56659 | 28.33613 | 33.71091 | 39.08747 | 42.55697 | 45.72229 | 49.58788 | 52.33562 |
| 30 | 13.78672 | 14.95346 | 16.79077 | 18.49266 | 20.59923 | 24.47761 | 29.33603 | 34.79974 | 40.25602 | 43.77297 | 46.97924 | 50.89218 | 53.67196 |
| Брой степени на свобода к | Ниво на значимост a | |||||
| 0,01 | 0,025 | 0.05 | 0,95 | 0,975 | 0.99 | |
| 1 | 6.6 | 5.0 | 3.8 | 0.0039 | 0.00098 | 0.00016 |
| 2 | 9.2 | 7.4 | 6.0 | 0.103 | 0.051 | 0.020 |
| 3 | 11.3 | 9.4 | 7.8 | 0.352 | 0.216 | 0.115 |
| 4 | 13.3 | 11.1 | 9.5 | 0.711 | 0.484 | 0.297 |
| 5 | 15.1 | 12.8 | 11.1 | 1.15 | 0.831 | 0.554 |
| 6 | 16.8 | 14.4 | 12.6 | 1.64 | 1.24 | 0.872 |
| 7 | 18.5 | 16.0 | 14.1 | 2.17 | 1.69 | 1.24 |
| 8 | 20.1 | 17.5 | 15.5 | 2.73 | 2.18 | 1.65 |
| 9 | 21.7 | 19.0 | 16.9 | 3.33 | 2.70 | 2.09 |
| 10 | 23.2 | 20.5 | 18.3 | 3.94 | 3.25 | 2.56 |
| 11 | 24.7 | 21.9 | 19.7 | 4.57 | 3.82 | 3.05 |
| 12 | 26.2 | 23.3 | 21 .0 | 5.23 | 4.40 | 3.57 |
| 13 | 27.7 | 24.7 | 22.4 | 5.89 | 5.01 | 4.11 |
| 14 | 29.1 | 26.1 | 23.7 | 6.57 | 5.63 | 4.66 |
| 15 | 30.6 | 27.5 | 25.0 | 7.26 | 6.26 | 5.23 |
| 16 | 32.0 | 28.8 | 26.3 | 7.96 | 6.91 | 5.81 |
| 17 | 33.4 | 30.2 | 27.6 | 8.67 | 7.56 | 6.41 |
| 18 | 34.8 | 31.5 | 28.9 | 9.39 | 8.23 | 7.01 |
| 19 | 36.2 | 32.9 | 30.1 | 10.1 | 8.91 | 7.63 |
| 20 | 37.6 | 34.2 | 31.4 | 10.9 | 9.59 | 8.26 |
| 21 | 38.9 | 35.5 | 32.7 | 11.6 | 10.3 | 8.90 |
| 22 | 40.3 | 36.8 | 33.9 | 12.3 | 11.0 | 9.54 |
| 23 | 41.6 | 38.1 | 35.2 | 13.1 | 11.7 | 10.2 |
| 24 | 43.0 | 39.4 | 36.4 | 13.8 | 12.4 | 10.9 |
| 25 | 44.3 | 40.6 | 37.7 | 14.6 | 13.1 | 11.5 |
| 26 | 45.6 | 41.9 | 38.9 | 15.4 | 13.8 | 12.2 |
| 27 | 47.0 | 43.2 | 40.1 | 16.2 | 14.6 | 12.9 |
| 28 | 48.3 | 44.5 | 41.3 | 16.9 | 15.3 | 13.6 |
| 29 | 49.6 | 45.7 | 42.6 | 17.7 | 16.0 | 14.3 |
| 30 | 50.9 | 47.0 | 43.8 | 18.5 | 16.8 | 15.0 |