توزیع Chi-square را در نظر بگیرید. با استفاده از تابع MS EXCELCH2.DIST() بیایید تابع توزیع و چگالی احتمال را رسم کنیم و استفاده از این توزیع را برای اهداف آمار ریاضی توضیح دهیم.
توزیع Chi-square (X 2، XI2،انگلیسیچی- مربعتوزیع) در روش های مختلف آمار ریاضی استفاده می شود:
- در طول ساخت و ساز؛
- در ;
- در (آیا داده های تجربی با فرض ما در مورد تابع توزیع نظری موافق هستند یا خیر، انگلیسی Goodness of-fit)
- در (برای تعیین رابطه بین دو متغیر طبقه بندی، آزمون مجذور کای انگلیسی ارتباط استفاده می شود).
تعریف: اگر x 1 , x 2 , …, x n متغیرهای تصادفی مستقلی هستند که روی N(0;1) توزیع شده اند، توزیع متغیر تصادفی Y=x 1 2 + x 2 2 +…+ x n 2 دارای توزیع X 2 با n درجه آزادی
توزیع X 2 به یک پارامتر به نام بستگی دارد درجات آزادی (df, درجهازآزادی). به عنوان مثال، هنگام ساخت تعداد درجات آزادیبرابر df=n-1 است که n اندازه است نمونه ها.
چگالی توزیع X 2
با فرمول بیان می شود:
نمودارهای تابع
توزیع X 2 دارای شکل نامتقارن، برابر با n، برابر با 2n.
در فایل نمونه در برگه نمودارداده شده است نمودارهای چگالی توزیعاحتمالات و تابع توزیع تجمعی.

دارایی مفید توزیع CH2
اجازه دهید x 1، x 2، ...، x n متغیرهای تصادفی مستقلی باشند که روی آنها توزیع شده است قانون عادی
با پارامترهای یکسان μ و σ و X avاست میانگین حسابیاین مقادیر x
سپس متغیر تصادفی yبرابر
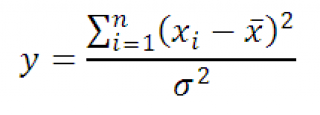
دارد X 2 -توزیعبا n-1 درجه آزادی. با استفاده از تعریف، عبارت فوق را می توان به صورت زیر بازنویسی کرد:

از این رو، توزیع نمونهآمار y، در نمونهاز توزیع نرمال، دارد X 2 -توزیعبا n-1 درجه آزادی.
زمانی که به این ملک نیاز خواهیم داشت. چون پراکندگیفقط می تواند یک عدد مثبت باشد، و X 2 -توزیعسپس برای ارزیابی آن استفاده می شود y d.b. > 0، همانطور که در تعریف آمده است.
توزیع CH2 در MS EXCEL
در MS EXCEL، از نسخه 2010، برای X 2 -توزیع هایک تابع خاص CHI2.DIST () وجود دارد، نام انگلیسی– CHISQ.DIST()، که به شما امکان محاسبه را می دهد چگالی احتمال(به فرمول بالا مراجعه کنید) و (احتمالی که یک متغیر تصادفی X دارد CI2-توزیع، مقدار کمتر یا مساوی x، P(X را خواهد گرفت<= x}).
توجه داشته باشید: چون توزیع CH2یک مورد خاص است، سپس فرمول =GAMMA.DIST(x;n/2;2;TRUE)برای عدد صحیح مثبت n همان نتیجه فرمول را برمی گرداند =CHI2.DIST(x;n; TRUE)یا =1-CHI2.DIST.PH(x;n) . و فرمول =GAMMA.DIST(x;n/2;2;FALSE)همان نتیجه فرمول را برمی گرداند =CHI2.DIST(x;n؛ FALSE)، یعنی چگالی احتمال توزیع CH2
تابع HI2.DIST.PH() برمی گردد تابع توزیعبه طور دقیق تر، احتمال سمت راست، i.e. P(X > x). بدیهی است که برابری درست است
=CHI2.DIST.PH(x;n)+CHI2.DIST(x;n;TRUE)=1
چون جمله اول احتمال P(X > x) را محاسبه می کند و جمله دوم P(X) را محاسبه می کند<= x}.
قبل از MS EXCEL 2010، EXCEL فقط تابع CHIDIST() را داشت که به شما امکان می دهد احتمال سمت راست را محاسبه کنید. P(X > x). قابلیت های توابع جدید MS EXCEL 2010 XI2.DIST() و XI2.DIST.PH() قابلیت های این تابع را پوشش می دهد. تابع ()CH2DIST برای سازگاری در MS EXCEL 2010 باقی مانده است.
() CHI2.DIST تنها تابعی است که برمیگرداند چگالی احتمال توزیع chi2(آگومان سوم باید FALSE باشد). بقیه توابع برمی گردند تابع توزیع تجمعی، یعنی احتمال اینکه متغیر تصادفی مقداری از محدوده مشخص شده بگیرد: P(X<= x}.
توابع فوق MS EXCEL در .
نمونه ها
بیایید این احتمال را پیدا کنیم که متغیر تصادفی X مقداری کمتر یا مساوی با مقدار داده شده بگیرد. x: P(X<= x}. Это можно сделать несколькими функциями:
CHI2.DIST(x; n; TRUE)
=1-HI2.DIST.PH(x; n)
=1-CHI2DIST(x; n)
تابع CH2.DIST.PH() احتمال P(X > x) را برمی گرداند، به اصطلاح احتمال سمت راست، بنابراین برای پیدا کردن P(X<= x}, необходимо вычесть ее результат от 1.
بیایید این احتمال را پیدا کنیم که متغیر تصادفی X مقداری بزرگتر از یک داده را بگیرد x: P(X > x). این را می توان با چندین عملکرد انجام داد:
1-CHI2.DIST(x; n; TRUE)
=HI2.DIST.PH(x; n)
=CHI2DIST(x; n)
تابع توزیع chi2 معکوس
برای محاسبه از تابع معکوس استفاده می شود آلفا- یعنی برای محاسبه مقادیر xبرای یک احتمال معین آلفا، و Xباید عبارت P(X را برآورده کند<= x}=آلفا.
تابع CH2.INV() برای محاسبه استفاده می شود فواصل اطمینان از واریانس توزیع نرمال.
تابع CHI2.OBR.PH() برای محاسبه استفاده می شود. اگر سطح معناداری به عنوان آرگومان برای تابع مشخص شود، برای مثال 0.05، آنگاه تابع مقداری از متغیر تصادفی x را برمیگرداند که برای آن P(X>x)=0.05 است. به عنوان مقایسه: تابع XI2.INR() مقداری از متغیر تصادفی x را برمی گرداند که برای آن P(X<=x}=0,05.
در MS EXCEL 2007 و قبل از آن، به جای HI2.OBR.PH() از تابع HI2OBR() استفاده شد.
توابع فوق را می توان تعویض کرد، زیرا فرمول های زیر همان نتیجه را نشان می دهند:
=CHI.OBR(alpha;n)
=HI2.OBR.PH(1-alpha;n)
=CHI2INV(1- آلفا;n)
چند نمونه از محاسبات در اینجا آورده شده است فایل نمونه در برگه توابع.
توابع MS EXCEL با استفاده از توزیع CH2
در زیر مکاتبات بین نام توابع روسی و انگلیسی آمده است:
CH2.DIST.PH() - انگلیسی. نام CHISQ.DIST.RT، یعنی. CHI-Squared DISTtribution Right Tail، توزیع Chi-square(d) دم راست
CH2.OBR() - انگلیسی. نام CHISQ.INV، یعنی. توزیع CHI-Squared INVerse
CH2.PH.OBR() - انگلیسی. نام CHISQ.INV.RT، یعنی. توزیع CHI-Squared INVerse Right Tail
CH2DIST() - انگلیسی. نام CHIDIST، تابعی معادل CHISQ.DIST.RT
CH2OBR() - انگلیسی. نام CHIINV، یعنی. توزیع CHI-Squared INVerse
تخمین پارامترهای توزیع
چون معمولا توزیع CH2برای اهداف آماری ریاضی (محاسبه فواصل اطمینان، آزمون فرضیه ها و غیره)و تقریباً هرگز برای ساخت مدل های مقادیر واقعی، پس برای این توزیع بحث تخمین پارامترهای توزیع در اینجا انجام نمی شود.
تقریب توزیع CI2 با توزیع نرمال
با تعداد درجه آزادی n>30 توزیع X 2به خوبی تقریب شده است توزیع نرمالبا مقدار متوسطμ=n و واریانس σ=2*n (نگاه کنید به نمونه فایل ورق تقریب).
آزمون \(\chi^2\) ("chi-square"، همچنین "آزمون خوب بودن تناسب پیرسون") کاربرد بسیار گسترده ای در آمار دارد. به طور کلی، می توان گفت که برای آزمایش فرضیه صفر استفاده می شود که یک متغیر تصادفی مشاهده شده تابع قانون توزیع نظری خاصی است (برای جزئیات بیشتر، به عنوان مثال، نگاه کنید به). فرمول خاص فرضیه مورد آزمایش از موردی به مورد دیگر متفاوت خواهد بود.
در این پست من نحوه عملکرد معیار \(\chi^2\) را با استفاده از یک مثال (فرضی) از ایمونولوژی شرح خواهم داد. بیایید تصور کنیم که آزمایشی برای تعیین اثربخشی سرکوب توسعه یک بیماری میکروبی زمانی که آنتیبادیهای مناسب وارد بدن میشوند، انجام دادهایم. در مجموع 111 موش در این آزمایش شرکت کردند که ما آنها را به دو گروه شامل 57 و 54 حیوان تقسیم کردیم. اولین گروه از موش ها با تزریق باکتری های بیماری زا و به دنبال آن سرم خون حاوی آنتی بادی علیه این باکتری ها معرفی شد. حیوانات از گروه دوم به عنوان کنترل خدمت کردند - آنها فقط تزریق باکتری دریافت کردند. پس از مدتی انکوباسیون، مشخص شد که 38 موش مردند و 73 موش زنده ماندند. از کشته شدگان 13 نفر متعلق به گروه اول و 25 نفر به گروه دوم (شاهد). فرضیه صفر آزمایش شده در این آزمایش را می توان به صورت زیر فرموله کرد: تجویز سرم با آنتی بادی ها هیچ تأثیری بر بقای موش ها ندارد. به عبارت دیگر، ما استدلال می کنیم که تفاوت های مشاهده شده در بقای موش (77.2٪ در گروه اول در مقابل 53.7٪ در گروه دوم) کاملا تصادفی است و به اثر آنتی بادی ها مربوط نمی شود.
داده های به دست آمده در آزمایش را می توان در قالب یک جدول ارائه کرد:
مجموع |
|||
باکتری + سرم |
|||
فقط باکتری |
|||
مجموع |
جداول مانند جدول نشان داده شده را جداول احتمالی می نامند. در مثال مورد بررسی، جدول دارای ابعاد 2x2 است: دو دسته از اشیا ("باکتری + سرم" و "فقط باکتری") وجود دارد که بر اساس دو معیار ("مرده" و "بازمانده شده") بررسی می شوند. این سادهترین حالت جدول احتمالی است: البته، هم تعداد کلاسهای مورد مطالعه و هم تعداد ویژگیها میتواند بیشتر باشد.
برای آزمایش فرضیه صفر ذکر شده در بالا، باید بدانیم اگر آنتی بادی ها واقعاً تأثیری بر بقای موش ها نداشته باشند، وضعیت چگونه خواهد بود. به عبارت دیگر، شما باید محاسبه کنید فرکانس های مورد انتظاربرای سلول های مربوطه از جدول احتمالی. چگونه این کار را انجام دهیم؟ در این آزمایش، در مجموع 38 موش مردند که 34.2 درصد از کل حیوانات درگیر را تشکیل می دهد. در صورتی که تجویز آنتی بادی بر بقای موش ها تأثیری نداشته باشد، باید درصد مرگ و میر یکسانی در هر دو گروه آزمایشی یعنی 2/34 درصد مشاهده شود. با محاسبه 34.2 درصد از 57 و 54، به 19.5 و 18.5 می رسیم. اینها میزان مرگ و میر مورد انتظار در گروه های آزمایشی ما است. نرخ بقای مورد انتظار به روش مشابهی محاسبه می شود: از آنجایی که در مجموع 73 موش زنده مانده اند، یا 65.8٪ از تعداد کل، نرخ بقای مورد انتظار 37.5 و 35.5 خواهد بود. بیایید یک جدول احتمالی جدید ایجاد کنیم، اکنون با فرکانس های مورد انتظار:
مرده |
بازماندگان |
مجموع |
|
باکتری + سرم |
|||
فقط باکتری |
|||
مجموع |
همانطور که می بینیم، فرکانس های مورد انتظار کاملاً با فرکانس های مشاهده شده متفاوت است. به نظر می رسد تجویز آنتی بادی ها بر بقای موش های آلوده به پاتوژن تأثیر دارد. ما میتوانیم این برداشت را با استفاده از تست تناسب پیرسون \(\chi^2\) کمی کنیم:
\[\chi^2 = \sum_()\frac((f_o - f_e)^2)(f_e),\]
که در آن \(f_o\) و \(f_e\) به ترتیب فرکانس های مشاهده شده و مورد انتظار هستند. جمع بندی در تمام سلول های جدول انجام می شود. بنابراین، برای مثال مورد بررسی ما داریم
\[\chi^2 = (13 - 19.5)^2/19.5 + (44 - 37.5)^2/37.5 + (25 - 18.5)^2/18.5 + (29 - 35.5)^2/35.5 = \]
آیا مقدار حاصل از \(\chi^2\) به اندازه ای بزرگ است که فرضیه صفر را رد کند؟ برای پاسخ به این سوال لازم است که ارزش بحرانی مربوط به معیار را پیدا کنیم. تعداد درجات آزادی برای \(\chi^2\) به صورت \(df = (R - 1) (C - 1)\) محاسبه می شود که \(R\) و \(C\) عدد هستند. از ردیف ها و ستون ها در ترکیب جدول. در مورد ما \(df = (2 -1)(2 - 1) = 1\). با دانستن تعداد درجات آزادی، اکنون میتوانیم به راحتی مقدار بحرانی \(\chi^2\) را با استفاده از تابع استاندارد R qchisq() دریابیم:
بنابراین، با یک درجه آزادی، تنها در 5٪ موارد، مقدار معیار \(\chi^2\) از 3.841 فراتر می رود. مقداری که به دست آوردیم، 6.79، به طور قابل توجهی از این مقدار بحرانی فراتر می رود، که به ما این حق را می دهد که فرضیه صفر را رد کنیم که هیچ ارتباطی بین تجویز آنتی بادی ها و بقای موش های آلوده وجود ندارد. با رد این فرضیه، خطر اشتباه با احتمال کمتر از 5٪ وجود دارد.
لازم به ذکر است که فرمول بالا برای معیار \(\chi^2\) هنگام کار با جداول احتمالی با اندازه 2x2 مقادیر کمی متورم می دهد. دلیل آن این است که توزیع معیار \(\chi^2\) به خودی خود پیوسته است، در حالی که فرکانس های ویژگی های باینری ("درگذشت" / "بقا") بنا به تعریف گسسته هستند. در این راستا، هنگام محاسبه معیار، مرسوم است که به اصطلاح معرفی می شود تصحیح تداوم، یا اصلاحیه یتس :
\[\chi^2_Y = \sum_()\frac((|f_o - f_e| - 0.5)^2)(f_e).\]
پیرسون "آزمون کای دو با یتس"داده های تصحیح تداوم: موش X-squared = 5.7923، df = 1، p-value = 0.0161
همانطور که می بینیم، R به طور خودکار تصحیح پیوستگی Yates را اعمال می کند ( آزمون کای دو پیرسون با تصحیح تداوم ییتس). مقدار \(\chi^2\) محاسبه شده توسط برنامه 5.79213 بود. ما میتوانیم فرضیه صفر عدم اثر آنتیبادی را در خطر اشتباه بودن با احتمال کمی بیش از 1% رد کنیم (p-value = 0.0161).
وزارت آموزش و پرورش و علوم فدراسیون روسیه
آژانس فدرال آموزش شهر ایرکوتسک
دانشگاه دولتی اقتصاد و حقوق بایکال
گروه انفورماتیک و سایبرنتیک
توزیع Chi-square و کاربردهای آن
کلمیکووا آنا آندریونا
دانشجوی سال دوم
گروه IS-09-1
برای پردازش داده های به دست آمده از آزمون کای اسکوئر استفاده می کنیم.
برای انجام این کار، جدولی از توزیع فرکانس های تجربی می سازیم. فرکانس هایی که مشاهده می کنیم:
از نظر تئوری، ما انتظار داریم که فرکانس ها به طور مساوی توزیع شوند، یعنی. فرکانس به طور متناسب بین پسران و دختران توزیع خواهد شد. بیایید جدولی از فرکانس های نظری بسازیم. برای انجام این کار، مجموع ردیف را در مجموع ستون ضرب کنید و عدد حاصل را بر مجموع کل (s) تقسیم کنید.
جدول نهایی برای محاسبات به صورت زیر خواهد بود:
χ2 = ∑(E - T)² / T
n = (R - 1)، که در آن R تعداد ردیف های جدول است.
در مورد ما، خی دو = 4.21; n = 2.
با استفاده از جدول مقادیر بحرانی معیار، متوجه می شویم: با n = 2 و سطح خطای 0.05، مقدار بحرانی χ2 = 5.99 است.
مقدار به دست آمده کمتر از مقدار بحرانی است، به این معنی که فرضیه صفر پذیرفته شده است.
نتیجه گیری: معلمان هنگام نوشتن ویژگی های کودک به جنسیت کودک اهمیت نمی دهند.
برنامه
نقاط بحرانی توزیع χ2
جدول 1

نتیجه گیری
دانش آموزان تقریباً همه تخصص ها در پایان دوره عالی ریاضیات بخش "تئوری احتمالات و آمار ریاضی" را مطالعه می کنند و در واقع فقط با برخی از مفاهیم و نتایج اولیه آشنا می شوند که به وضوح برای کار عملی کافی نیست. دانشآموزان در دروس ویژه با برخی از روشهای تحقیق ریاضی آشنا میشوند (مثلاً «پیشبینی و برنامهریزی فنی و اقتصادی»، «تحلیل فنی و اقتصادی»، «کنترل کیفیت محصول»، «بازاریابی»، «کنترل»، «روشهای ریاضی پیشبینی». ") "، "آمار"، و غیره - در مورد دانشجویان تخصص های اقتصادی)، با این حال، ارائه در بیشتر موارد ماهیت بسیار مختصر و فرمولی دارد. در نتیجه، دانش متخصصان آمار کاربردی ناکافی است.
بنابراین، درس «آمار کاربردی» در دانشگاههای فنی و درس «اقتصاد سنجی» در دانشگاههای اقتصادی، از آنجایی که اقتصاد سنجی همان طور که میدانیم، تحلیل آماری دادههای اقتصادی خاص است، از اهمیت بالایی برخوردار است.
تئوری احتمال و آمار ریاضی دانش بنیادی را برای آمار کاربردی و اقتصاد سنجی فراهم می کند.
آنها برای کار عملی برای متخصصان ضروری هستند.
من به مدل احتمالی پیوسته نگاه کردم و سعی کردم کاربرد آن را با مثال هایی نشان دهم.
فهرست ادبیات استفاده شده
1. Orlov A.I. آمار کاربردی م.: انتشارات "امتحان"، 2004.
2. Gmurman V.E. نظریه احتمالات و آمار ریاضی. م.: مدرسه عالی، 1999. – 479 ص.
3. آیووزیان س.ا. نظریه احتمالات و آمار کاربردی، جلد 1. م.: وحدت، 2001. – 656 ص.
4. Khamitov G.P., Vedernikova T.I. احتمالات و آمار. ایرکوتسک: BGUEP، 2006 – 272 p.
5. ژووا ال.ن. اقتصاد سنجی. Irkutsk: BGUEP، 2002. – 314 p.
6. Mosteller F. پنجاه مسئله احتمالی سرگرم کننده با راه حل. M.: Nauka، 1975. – 111 p.
7. Mosteller F. احتمال. م.: میر، 1969. – 428 ص.
8. Yaglom A.M. احتمال و اطلاعات M.: Nauka، 1973. – 511 p.
9. چیستیاکوف وی.پی. درس تئوری احتمال. M.: Nauka، 1982. – 256 p.
10. کرمر ن.ش. نظریه احتمالات و آمار ریاضی. م.: وحدت، 2000. - 543 ص.
11. دایره المعارف ریاضی، ج1. م.: دایره المعارف شوروی، 1976. – 655 ص.
12. http://psystat.at.ua/ - آمار در روانشناسی و آموزش. آزمون مجذور کای مقاله.
تا پایان قرن نوزدهم، توزیع نرمال به عنوان قانون جهانی تنوع در داده ها در نظر گرفته می شد. با این حال، K. Pearson اشاره کرد که فرکانس های تجربی می توانند تا حد زیادی با توزیع نرمال متفاوت باشند. این سوال مطرح شد که چگونه می توان این را ثابت کرد. نه تنها یک مقایسه گرافیکی، که ذهنی است، لازم بود، بلکه یک توجیه کمی دقیق نیز لازم بود.
اینگونه معیار اختراع شد χ 2(کای مربع)، که اهمیت اختلاف بین فرکانس های تجربی (مشاهده شده) و نظری (مورد انتظار) را آزمایش می کند. این در سال 1900 اتفاق افتاد، اما این معیار هنوز در حال استفاده است. علاوه بر این، برای حل طیف گسترده ای از مشکلات سازگار شده است. اول از همه، این تجزیه و تحلیل داده های طبقه بندی است، یعنی. آنهایی که نه با کمیت، بلکه با تعلق به دسته ای بیان می شوند. به عنوان مثال، کلاس ماشین، جنسیت شرکت کننده آزمایش، نوع گیاه و غیره. عمليات رياضي مانند جمع و ضرب را نمي توان براي چنين داده هايي به كار برد.
فرکانس های مشاهده شده را نشان می دهیم درباره (مشاهده شده)، مورد انتظار - E (مورد انتظار). به عنوان مثال، نتیجه 60 بار چرخاندن قالب را در نظر می گیریم. اگر متقارن و یکنواخت باشد، احتمال گرفتن هر ضلع 1/6 است و بنابراین تعداد مورد انتظار گرفتن هر ضلع 10 (1/6∙60) است. فرکانس های مشاهده شده و مورد انتظار را در جدول می نویسیم و هیستوگرام رسم می کنیم.

فرضیه صفر این است که فرکانس ها سازگار هستند، یعنی داده های واقعی با داده های مورد انتظار مغایرت ندارند. یک فرضیه جایگزین این است که انحرافات در فرکانس ها فراتر از نوسانات تصادفی است، اختلافات از نظر آماری معنی دار هستند. برای نتیجه گیری دقیق، ما نیاز داریم.
- اندازه گیری خلاصه ای از اختلاف بین فرکانس های مشاهده شده و مورد انتظار.
- توزیع این اندازه گیری در صورتی که فرضیه عدم وجود تفاوت درست باشد.
بیایید با فاصله بین فرکانس ها شروع کنیم. اگر فقط تفاوت را در نظر بگیرید O - E، پس چنین اندازه گیری به مقیاس داده ها (فرکانس ها) بستگی دارد. به عنوان مثال، 20 - 5 = 15 و 1020 - 1005 = 15. در هر دو مورد، تفاوت 15 است. اما در حالت اول، فرکانس های مورد انتظار 3 برابر کمتر از موارد مشاهده شده و در حالت دوم - فقط 1.5 است. ٪. ما به یک معیار نسبی نیاز داریم که به مقیاس بستگی نداشته باشد.
اجازه دهید به حقایق زیر توجه کنیم. به طور کلی، تعداد دستههایی که فرکانسها در آنها اندازهگیری میشوند، میتواند بسیار بیشتر باشد، بنابراین احتمال اینکه یک مشاهده منفرد در یک دسته یا دسته دیگر قرار گیرد بسیار کم است. اگر چنین است، پس توزیع چنین متغیر تصادفی از قانون رویدادهای نادر، معروف به قانون پواسون. در قانون پواسون، همانطور که مشخص است، مقدار انتظارات ریاضی و واریانس بر هم منطبق هستند (پارامتر λ ). این بدان معنی است که فرکانس مورد انتظار برای برخی از دسته های متغیر اسمی است E iهمزمان و پراکندگی آن خواهد بود. علاوه بر این، قانون پواسون با تعداد زیادی مشاهدات به حالت عادی گرایش دارد. با ترکیب این دو واقعیت، به این نتیجه می رسیم که اگر فرضیه تطابق بین فرکانس های مشاهده شده و مورد انتظار درست باشد، آنگاه، با تعداد زیادی مشاهدات، بیان
مهم است که به یاد داشته باشید که نرمال بودن فقط در فرکانس های به اندازه کافی بالا ظاهر می شود. در آمار، به طور کلی پذیرفته شده است که تعداد کل مشاهدات (مجموع فرکانس ها) باید حداقل 50 باشد و فرکانس مورد انتظار در هر درجه بندی باید حداقل 5 باشد. فقط در این مورد، مقدار نشان داده شده در بالا دارای توزیع نرمال استاندارد است. . فرض کنیم این شرط برقرار است.
توزیع نرمال استاندارد تقریباً همه مقادیر را در 3± (قاعده سه سیگما) دارد. بنابراین، ما تفاوت نسبی در فرکانس ها را برای یک درجه بندی به دست آوردیم. ما به یک معیار قابل تعمیم نیاز داریم. شما نمی توانید فقط تمام انحرافات را جمع کنید - ما 0 را دریافت می کنیم (حدس بزنید چرا). پیرسون پیشنهاد کرد مجذورهای این انحرافات را جمع کنید.
![]()
این علامت است تست کای دو پیرسون. اگر فرکانسها واقعاً با فرکانسهای مورد انتظار مطابقت داشته باشند، ارزش معیار نسبتاً کوچک خواهد بود (زیرا اکثر انحرافات در حدود صفر هستند). اما اگر معیار بزرگ باشد، این نشان دهنده تفاوت قابل توجهی بین فرکانس ها است.
معیار پیرسون زمانی "بزرگ" می شود که وقوع چنین یا حتی بیشتر از آن بعید باشد. و برای محاسبه چنین احتمالی، لازم است که توزیع معیار را زمانی که آزمایش بارها تکرار می شود، زمانی که فرضیه توافق فرکانس صحیح است، دانست.
همانطور که به راحتی قابل مشاهده است، مقدار خی دو به تعداد عبارت ها نیز بستگی دارد. هرچه تعداد آنها بیشتر باشد، ارزش معیار باید بیشتر باشد، زیرا هر عبارت به کل کمک می کند. بنابراین، برای هر مقدار مستقلشرایط، توزیع خود را وجود خواهد داشت. معلوم می شود که χ 2یک خانواده کامل از توزیع ها است.
و در اینجا به یک لحظه حساس می رسیم. عدد چیست مستقلشرایط به نظر می رسد هر اصطلاحی (یعنی انحراف) مستقل است. کی. پیرسون نیز چنین فکر می کرد، اما معلوم شد که اشتباه می کند. در واقع تعداد عبارت های مستقل یک عدد کمتر از تعداد درجه بندی متغیر اسمی خواهد بود n. چرا؟ زیرا اگر نمونهای داشته باشیم که مجموع فرکانسها قبلاً محاسبه شده باشد، همیشه میتوان یکی از فرکانسها را به عنوان تفاوت بین تعداد کل و مجموع همه فرکانسها تعیین کرد. از این رو این تنوع تا حدودی کمتر خواهد بود. رونالد فیشر 20 سال پس از آنکه پیرسون معیار خود را توسعه داد متوجه این واقعیت شد. حتی میزها باید دوباره درست می شدند.
به همین مناسبت، فیشر مفهوم جدیدی را وارد آمار کرد - درجه آزادی(درجات آزادی)، که نشان دهنده تعداد اصطلاحات مستقل در مجموع است. مفهوم درجات آزادی توضیحی ریاضی دارد و فقط در توزیع های مرتبط با نرمال ظاهر می شود (Student's، Fisher-Snedecor و خود chi-square).
برای درک بهتر معنای درجات آزادی، اجازه دهید به یک آنالوگ فیزیکی بپردازیم. بیایید یک نقطه را تصور کنیم که آزادانه در فضا حرکت می کند. 3 درجه آزادی دارد، زیرا می تواند در هر جهت در فضای سه بعدی حرکت کند. اگر نقطه ای در امتداد هر سطحی حرکت کند، آنگاه دو درجه آزادی (جلو و عقب، چپ و راست) دارد، اگرچه همچنان در فضای سه بعدی قرار دارد. نقطه ای که در امتداد چشمه حرکت می کند دوباره در فضای سه بعدی قرار دارد، اما تنها یک درجه آزادی دارد، زیرا می تواند به جلو یا عقب حرکت کند. همانطور که می بینید، فضایی که جسم در آن قرار دارد همیشه با آزادی حرکت واقعی مطابقت ندارد.
تقریباً به همین ترتیب، توزیع یک معیار آماری ممکن است به تعداد عناصر کمتری نسبت به شرایط مورد نیاز برای محاسبه آن بستگی داشته باشد. به طور کلی، تعداد درجات آزادی کمتر از تعداد مشاهدات بر اساس تعداد وابستگی های موجود است.
بنابراین، توزیع کای دو ( χ 2) خانواده ای از توزیع ها است که هر کدام به پارامتر درجه آزادی بستگی دارد. و تعریف رسمی آزمون کای اسکوئر به شرح زیر است. توزیع χ 2(chi-square) s کدرجه آزادی توزیع مجموع مربعات است کمتغیرهای تصادفی عادی استاندارد مستقل
در مرحله بعد، میتوانیم به خود فرمول برویم که تابع توزیع کایدو محاسبه میشود، اما خوشبختانه، همه چیز برای ما مدتهاست محاسبه شده است. برای به دست آوردن احتمال علاقه، می توانید از جدول آماری مناسب یا یک تابع آماده در اکسل استفاده کنید.
جالب است ببینید که چگونه شکل توزیع کای دو بسته به تعداد درجات آزادی تغییر می کند.

با افزایش درجات آزادی، توزیع کای اسکوئر نرمال است. این با عمل قضیه حد مرکزی توضیح داده می شود که بر اساس آن مجموع تعداد زیادی از متغیرهای تصادفی مستقل دارای توزیع نرمال است. در مورد مربع چیزی نمی گوید)).
آزمون فرضیه با استفاده از آزمون کای اسکوئر پیرسون
حال به آزمون فرضیه ها با استفاده از روش کای دو می رسیم. به طور کلی، فناوری باقی می ماند. فرضیه صفر این است که فرکانس های مشاهده شده با فرکانس های مورد انتظار مطابقت دارند (یعنی هیچ تفاوتی بین آنها وجود ندارد زیرا آنها از یک جمعیت گرفته شده اند). اگر اینطور باشد، پراکندگی نسبتاً کوچک و در محدوده نوسانات تصادفی خواهد بود. اندازه گیری پراکندگی با استفاده از آزمون کای دو تعیین می شود. سپس، یا خود معیار با مقدار بحرانی مقایسه می شود (برای سطح معنی داری و درجات آزادی متناظر)، یا درست تر، مقدار p مشاهده شده محاسبه می شود، یعنی. احتمال به دست آوردن مقدار معیار یکسان یا حتی بیشتر در صورت صحت فرضیه صفر.

چون ما علاقه مند به توافق فرکانس ها هستیم، در این صورت زمانی که معیار بزرگتر از سطح بحرانی باشد، این فرضیه رد می شود. آن ها معیار یک طرفه است با این حال، گاهی (گاهی) لازم است که فرضیه سمت چپ را آزمایش کنیم. به عنوان مثال، زمانی که داده های تجربی بسیار شبیه به داده های نظری هستند. سپس معیار ممکن است در یک منطقه بعید باشد، اما در سمت چپ. واقعیت این است که در شرایط طبیعی بعید است که فرکانس هایی را بدست آوریم که عملاً با فرکانس های نظری مطابقت دارند. همیشه یک مقدار تصادفی وجود دارد که خطا می دهد. اما اگر چنین خطایی وجود نداشته باشد، احتمالاً داده ها جعل شده اند. اما با این حال، فرضیه سمت راست معمولاً آزمایش می شود.
بیایید به مشکل تاس برگردیم. اجازه دهید با استفاده از داده های موجود، مقدار آزمون کای دو را محاسبه کنیم.
حالا بیایید مقدار بحرانی را در 5 درجه آزادی پیدا کنیم ( ک) و سطح معنی داری 0.05 ( α با توجه به جدول مقادیر بحرانی توزیع کای دو.

یعنی توزیع 0.05 چندک مربع چی (دم سمت راست) با 5 درجه آزادی χ 2 0.05; 5 = 11,1.
بیایید مقادیر واقعی و جدول بندی شده را با هم مقایسه کنیم. 3.4 ( χ 2) < 11,1 (χ 2 0.05; 5). معیار محاسبه شده کوچکتر است، به این معنی که فرضیه برابری (توافق) فرکانس ها رد نمی شود. در شکل وضعیت به این صورت است.

اگر مقدار محاسبه شده در ناحیه بحرانی باشد، فرض صفر رد می شود.
درست تر است که مقدار p را نیز محاسبه کنیم. برای انجام این کار، باید نزدیکترین مقدار را در جدول برای تعداد معینی از درجه آزادی پیدا کنید و به سطح اهمیت مربوطه نگاه کنید. اما این قرن گذشته است. ما از یک کامپیوتر، به ویژه MS Excel استفاده خواهیم کرد. اکسل چندین توابع مرتبط با مربع کای دارد.

در زیر شرح مختصری از آنها آورده شده است.
CH2.OBR- مقدار بحرانی معیار در یک احتمال معین در سمت چپ (مانند جداول آماری)
CH2.OBR.PH- ارزش بحرانی معیار برای یک احتمال معین در سمت راست. تابع اساساً تابع قبلی را کپی می کند. اما در اینجا می توانید بلافاصله سطح را نشان دهید α ، به جای کم کردن آن از 1. این راحت تر است، زیرا در بیشتر موارد، این دم سمت راست توزیع است که مورد نیاز است.
CH2.DIST- مقدار p در سمت چپ (چگالی قابل محاسبه است).
CH2.DIST.PH- مقدار p در سمت راست.
CHI2.TEST– فوراً یک آزمایش کای دو برای دو محدوده فرکانس انجام می دهد. تعداد درجات آزادی یک کمتر از تعداد فرکانسهای ستون (همانطور که باید باشد) در نظر گرفته میشود و یک مقدار p برمیگرداند.
بیایید برای آزمایش خود مقدار بحرانی (جدولی) را برای 5 درجه آزادی و آلفا 0.05 محاسبه کنیم. فرمول اکسل به شکل زیر خواهد بود:
CH2.OBR(0.95;5)
CH2.OBR.PH(0.05;5)
نتیجه یکسان خواهد بود - 11.0705. این مقداری است که در جدول می بینیم (به 1 رقم اعشار گرد شده است).
اجازه دهید در نهایت مقدار p را برای معیار 5 درجه آزادی محاسبه کنیم χ 2= 3.4. ما به احتمال سمت راست نیاز داریم، بنابراین تابع را با اضافه کردن HH (دم سمت راست) می گیریم.
CH2.DIST.PH(3.4;5) = 0.63857
یعنی با 5 درجه آزادی احتمال به دست آوردن مقدار معیار وجود دارد χ 2= 3.4 و بیشتر برابر با 64٪ است. به طور طبیعی، فرضیه رد نمی شود (p-value بیشتر از 5٪ است، فرکانس ها مطابقت بسیار خوبی دارند.
حال بیایید با استفاده از آزمون مجذور کای و تابع اکسل CHI2.TEST، فرضیه مطابقت فرکانس ها را بررسی کنیم.

بدون جدول، بدون محاسبات دست و پا گیر. با تعیین ستون هایی با فرکانس های مشاهده شده و مورد انتظار به عنوان آرگومان های تابع، بلافاصله مقدار p را بدست می آوریم. زیبایی
حالا تصور کنید که با یک مرد مشکوک تاس بازی می کنید. توزیع امتیازات از 1 تا 5 ثابت می ماند، اما او 26 عدد شش می زند (تعداد کل پرتاب ها 78 می شود).

مقدار p در این مورد 0.003 است که بسیار کمتر از 0.05 است. دلایل خوبی برای شک در اعتبار تاس وجود دارد. در اینجا این احتمال در نمودار توزیع خی دو به نظر می رسد.

خود معیار کای اسکوئر در اینجا 17.8 است که طبیعتاً از جدول یک (11.1) بزرگتر است.
امیدوارم تونسته باشم توضیح بدم که ملاک توافق چیه χ 2(Pearson chi-square) و اینکه چگونه می توان از آن برای آزمون فرضیه های آماری استفاده کرد.
در نهایت یک بار دیگر در مورد یک شرط مهم! تست کای اسکوئر فقط زمانی درست کار می کند که تعداد همه فرکانس ها از 50 بیشتر شود و حداقل مقدار مورد انتظار برای هر درجه بندی کمتر از 5 نباشد. اگر در هر دسته ای فرکانس مورد انتظار کمتر از 5 باشد، اما مجموع همه فرکانس ها بیشتر از آن باشد. 50، آنگاه چنین مقوله ای با نزدیکترین آنها ترکیب می شود تا فرکانس کل آنها از 5 تجاوز کند. اگر این امکان وجود ندارد یا مجموع فرکانس ها کمتر از 50 است، باید از روش های دقیق تری برای آزمون فرضیه استفاده کرد. در مورد آنها یک بار دیگر صحبت خواهیم کرد.
در زیر ویدیویی در مورد نحوه آزمایش فرضیه در اکسل با استفاده از آزمون کای دو وجود دارد.
اجازه دهید U 1, U 2, ..,U k مقادیر نرمال استاندارد مستقل باشند. توزیع متغیر تصادفی K = U 1 2 +U 2 2 + .. + U k 2 را توزیع کای دو با کدرجه آزادی (K~χ 2 (k) را بنویسید). این یک توزیع یکوجهی با چولگی مثبت و ویژگیهای زیر است: حالت M=k-2 انتظار ریاضی m=k واریانس D=2k (شکل). با مقدار به اندازه کافی بزرگ از پارامتر کتوزیع χ 2 (k) دارای توزیع تقریباً نرمال با پارامترها است
هنگام حل مسائل آمار ریاضی، بسته به احتمال داده شده α و تعداد درجات آزادی، از نقاط بحرانی χ 2 (k) استفاده می شود. ک(پیوست 2). نقطه بحرانی Χ 2 kr = Χ 2 (k; α) مرز ناحیه ای است که در سمت راست آن 100- α % از سطح زیر منحنی چگالی توزیع قرار دارد. احتمال اینکه مقدار متغیر تصادفی K~χ 2 (k) در طول آزمایش به سمت راست نقطه χ 2 (k) بیفتد از α P(K≥χ 2 kp)≤ α تجاوز نمی کند. به عنوان مثال، برای متغیر تصادفی K~χ 2 (20) ما احتمال α=0.05 را تعیین می کنیم. با استفاده از جدول نقاط بحرانی توزیع کای دو (جدول)، χ 2 kp = χ 2 (20; 0.05) = 31.4 را پیدا می کنیم. این به این معنی است که احتمال این متغیر تصادفی است کمقداری بزرگتر از 31.4، کمتر از 0.05 (شکل). 
برنج. نمودار چگالی توزیع χ 2 (k) برای مقادیر مختلف تعداد درجات آزادی ک
نقاط بحرانی χ 2 (k) در ماشین حساب های زیر استفاده می شود:
- بررسی چند خطی بودن (درباره چند خطی).
بنابراین، برای بررسی جهت اتصال، تحلیل همبستگی، به ویژه آزمون فرضیه با استفاده از ضریب همبستگی پیرسون با آزمایش بیشتر برای معناداری با استفاده از آزمون t انتخاب میشود.
برای هر مقدار از سطح اهمیت α Χ 2 را می توان با استفاده از تابع MS Excel پیدا کرد: =HI2OBR(α؛ درجه آزادی)
| n-1 | .995 | .990 | .975 | .950 | .900 | .750 | .500 | .250 | .100 | .050 | .025 | .010 | .005 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.00004 | 0.00016 | 0.00098 | 0.00393 | 0.01579 | 0.10153 | 0.45494 | 1.32330 | 2.70554 | 3.84146 | 5.02389 | 6.63490 | 7.87944 |
| 2 | 0.01003 | 0.02010 | 0.05064 | 0.10259 | 0.21072 | 0.57536 | 1.38629 | 2.77259 | 4.60517 | 5.99146 | 7.37776 | 9.21034 | 10.59663 |
| 3 | 0.07172 | 0.11483 | 0.21580 | 0.35185 | 0.58437 | 1.21253 | 2.36597 | 4.10834 | 6.25139 | 7.81473 | 9.34840 | 11.34487 | 12.83816 |
| 4 | 0.20699 | 0.29711 | 0.48442 | 0.71072 | 1.06362 | 1.92256 | 3.35669 | 5.38527 | 7.77944 | 9.48773 | 11.14329 | 13.27670 | 14.86026 |
| 5 | 0.41174 | 0.55430 | 0.83121 | 1.14548 | 1.61031 | 2.67460 | 4.35146 | 6.62568 | 9.23636 | 11.07050 | 12.83250 | 15.08627 | 16.74960 |
| 6 | 0.67573 | 0.87209 | 1.23734 | 1.63538 | 2.20413 | 3.45460 | 5.34812 | 7.84080 | 10.64464 | 12.59159 | 14.44938 | 16.81189 | 18.54758 |
| 7 | 0.98926 | 1.23904 | 1.68987 | 2.16735 | 2.83311 | 4.25485 | 6.34581 | 9.03715 | 12.01704 | 14.06714 | 16.01276 | 18.47531 | 20.27774 |
| 8 | 1.34441 | 1.64650 | 2.17973 | 2.73264 | 3.48954 | 5.07064 | 7.34412 | 10.21885 | 13.36157 | 15.50731 | 17.53455 | 20.09024 | 21.95495 |
| 9 | 1.73493 | 2.08790 | 2.70039 | 3.32511 | 4.16816 | 5.89883 | 8.34283 | 11.38875 | 14.68366 | 16.91898 | 19.02277 | 21.66599 | 23.58935 |
| 10 | 2.15586 | 2.55821 | 3.24697 | 3.94030 | 4.86518 | 6.73720 | 9.34182 | 12.54886 | 15.98718 | 18.30704 | 20.48318 | 23.20925 | 25.18818 |
| 11 | 2.60322 | 3.05348 | 3.81575 | 4.57481 | 5.57778 | 7.58414 | 10.34100 | 13.70069 | 17.27501 | 19.67514 | 21.92005 | 24.72497 | 26.75685 |
| 12 | 3.07382 | 3.57057 | 4.40379 | 5.22603 | 6.30380 | 8.43842 | 11.34032 | 14.84540 | 18.54935 | 21.02607 | 23.33666 | 26.21697 | 28.29952 |
| 13 | 3.56503 | 4.10692 | 5.00875 | 5.89186 | 7.04150 | 9.29907 | 12.33976 | 15.98391 | 19.81193 | 22.36203 | 24.73560 | 27.68825 | 29.81947 |
| 14 | 4.07467 | 4.66043 | 5.62873 | 6.57063 | 7.78953 | 10.16531 | 13.33927 | 17.11693 | 21.06414 | 23.68479 | 26.11895 | 29.14124 | 31.31935 |
| 15 | 4.60092 | 5.22935 | 6.26214 | 7.26094 | 8.54676 | 11.03654 | 14.33886 | 18.24509 | 22.30713 | 24.99579 | 27.48839 | 30.57791 | 32.80132 |
| 16 | 5.14221 | 5.81221 | 6.90766 | 7.96165 | 9.31224 | 11.91222 | 15.33850 | 19.36886 | 23.54183 | 26.29623 | 28.84535 | 31.99993 | 34.26719 |
| 17 | 5.69722 | 6.40776 | 7.56419 | 8.67176 | 10.08519 | 12.79193 | 16.33818 | 20.48868 | 24.76904 | 27.58711 | 30.19101 | 33.40866 | 35.71847 |
| 18 | 6.26480 | 7.01491 | 8.23075 | 9.39046 | 10.86494 | 13.67529 | 17.33790 | 21.60489 | 25.98942 | 28.86930 | 31.52638 | 34.80531 | 37.15645 |
| 19 | 6.84397 | 7.63273 | 8.90652 | 10.11701 | 11.65091 | 14.56200 | 18.33765 | 22.71781 | 27.20357 | 30.14353 | 32.85233 | 36.19087 | 38.58226 |
| 20 | 7.43384 | 8.26040 | 9.59078 | 10.85081 | 12.44261 | 15.45177 | 19.33743 | 23.82769 | 28.41198 | 31.41043 | 34.16961 | 37.56623 | 39.99685 |
| 21 | 8.03365 | 8.89720 | 10.28290 | 11.59131 | 13.23960 | 16.34438 | 20.33723 | 24.93478 | 29.61509 | 32.67057 | 35.47888 | 38.93217 | 41.40106 |
| 22 | 8.64272 | 9.54249 | 10.98232 | 12.33801 | 14.04149 | 17.23962 | 21.33704 | 26.03927 | 30.81328 | 33.92444 | 36.78071 | 40.28936 | 42.79565 |
| 23 | 9.26042 | 10.19572 | 11.68855 | 13.09051 | 14.84796 | 18.13730 | 22.33688 | 27.14134 | 32.00690 | 35.17246 | 38.07563 | 41.63840 | 44.18128 |
| 24 | 9.88623 | 10.85636 | 12.40115 | 13.84843 | 15.65868 | 19.03725 | 23.33673 | 28.24115 | 33.19624 | 36.41503 | 39.36408 | 42.97982 | 45.55851 |
| 25 | 10.51965 | 11.52398 | 13.11972 | 14.61141 | 16.47341 | 19.93934 | 24.33659 | 29.33885 | 34.38159 | 37.65248 | 40.64647 | 44.31410 | 46.92789 |
| 26 | 11.16024 | 12.19815 | 13.84390 | 15.37916 | 17.29188 | 20.84343 | 25.33646 | 30.43457 | 35.56317 | 38.88514 | 41.92317 | 45.64168 | 48.28988 |
| 27 | 11.80759 | 12.87850 | 14.57338 | 16.15140 | 18.11390 | 21.74940 | 26.33634 | 31.52841 | 36.74122 | 40.11327 | 43.19451 | 46.96294 | 49.64492 |
| 28 | 12.46134 | 13.56471 | 15.30786 | 16.92788 | 18.93924 | 22.65716 | 27.33623 | 32.62049 | 37.91592 | 41.33714 | 44.46079 | 48.27824 | 50.99338 |
| 29 | 13.12115 | 14.25645 | 16.04707 | 17.70837 | 19.76774 | 23.56659 | 28.33613 | 33.71091 | 39.08747 | 42.55697 | 45.72229 | 49.58788 | 52.33562 |
| 30 | 13.78672 | 14.95346 | 16.79077 | 18.49266 | 20.59923 | 24.47761 | 29.33603 | 34.79974 | 40.25602 | 43.77297 | 46.97924 | 50.89218 | 53.67196 |
| تعداد درجات آزادی ک | سطح اهمیت الف | |||||
| 0,01 | 0,025 | 0.05 | 0,95 | 0,975 | 0.99 | |
| 1 | 6.6 | 5.0 | 3.8 | 0.0039 | 0.00098 | 0.00016 |
| 2 | 9.2 | 7.4 | 6.0 | 0.103 | 0.051 | 0.020 |
| 3 | 11.3 | 9.4 | 7.8 | 0.352 | 0.216 | 0.115 |
| 4 | 13.3 | 11.1 | 9.5 | 0.711 | 0.484 | 0.297 |
| 5 | 15.1 | 12.8 | 11.1 | 1.15 | 0.831 | 0.554 |
| 6 | 16.8 | 14.4 | 12.6 | 1.64 | 1.24 | 0.872 |
| 7 | 18.5 | 16.0 | 14.1 | 2.17 | 1.69 | 1.24 |
| 8 | 20.1 | 17.5 | 15.5 | 2.73 | 2.18 | 1.65 |
| 9 | 21.7 | 19.0 | 16.9 | 3.33 | 2.70 | 2.09 |
| 10 | 23.2 | 20.5 | 18.3 | 3.94 | 3.25 | 2.56 |
| 11 | 24.7 | 21.9 | 19.7 | 4.57 | 3.82 | 3.05 |
| 12 | 26.2 | 23.3 | 21 .0 | 5.23 | 4.40 | 3.57 |
| 13 | 27.7 | 24.7 | 22.4 | 5.89 | 5.01 | 4.11 |
| 14 | 29.1 | 26.1 | 23.7 | 6.57 | 5.63 | 4.66 |
| 15 | 30.6 | 27.5 | 25.0 | 7.26 | 6.26 | 5.23 |
| 16 | 32.0 | 28.8 | 26.3 | 7.96 | 6.91 | 5.81 |
| 17 | 33.4 | 30.2 | 27.6 | 8.67 | 7.56 | 6.41 |
| 18 | 34.8 | 31.5 | 28.9 | 9.39 | 8.23 | 7.01 |
| 19 | 36.2 | 32.9 | 30.1 | 10.1 | 8.91 | 7.63 |
| 20 | 37.6 | 34.2 | 31.4 | 10.9 | 9.59 | 8.26 |
| 21 | 38.9 | 35.5 | 32.7 | 11.6 | 10.3 | 8.90 |
| 22 | 40.3 | 36.8 | 33.9 | 12.3 | 11.0 | 9.54 |
| 23 | 41.6 | 38.1 | 35.2 | 13.1 | 11.7 | 10.2 |
| 24 | 43.0 | 39.4 | 36.4 | 13.8 | 12.4 | 10.9 |
| 25 | 44.3 | 40.6 | 37.7 | 14.6 | 13.1 | 11.5 |
| 26 | 45.6 | 41.9 | 38.9 | 15.4 | 13.8 | 12.2 |
| 27 | 47.0 | 43.2 | 40.1 | 16.2 | 14.6 | 12.9 |
| 28 | 48.3 | 44.5 | 41.3 | 16.9 | 15.3 | 13.6 |
| 29 | 49.6 | 45.7 | 42.6 | 17.7 | 16.0 | 14.3 |
| 30 | 50.9 | 47.0 | 43.8 | 18.5 | 16.8 | 15.0 |